Vítejte na naší první sérii keší, která vás seznámí s demografií jako vědou, přiblíží, čím se zabývá a ukáže některé základy demografické analýzy. Zdá se, že u nás na toto téma ještě nikdo žádnou kešku nezaložil, proto má série za cíl ukázat tuto méně známou vědní disciplínu na pomezí přírodních a sociálních věd a snad i zaujmout :). Série má 10 keší a jednu bonusovou kešku navíc, nezapomeňte si proto vždy opsat bonusové číslo! Série je koncipovaná tak, aby byla vhodná i pro kolo a dala se odlovit naráz, pouze čísla keší neodpovídají pořadí v mapě.
TABULKY ŽIVOTA
Tabulky života neboli demografické tabulky jsou uspořádané řady vzájemně propojených veličin popisujících průběh jednoho nebo více demografických procesů. Jejich použití je v demografii velmi časté a potřebné. Jedná se o vytvoření matematického modelu chování určité populace. Jednotlivé ukazatele se vyjadřují v jednotném měřítku, nazývaném kořen tabulky (obvykle se údaje v tabulce přepočítávají na 100 tisíc osob, respektive na jakoukoliv jinou mocninu deseti). Ačkoliv se může zdát, že je vypočítat tabulku relativně složité, jedná se pouze o jednoduché matematické operace na úrovni základní školy. Stačí jen trocha cviku a počítání budete dávat bez problému z hlavy.
Prvním a nejčastěji používaným typem jsou úmrtnostní tabulky, jejichž koncepci navrhl John Graunt, ale podrobněji popsal až Edmund Halley v 17. století. Za jejich pomoci lze kvantitativně nejpřesněji vyjádřit intenzitu úmrtnosti zkoumané populace. Dalšími příklady tabulek života jsou například tabulky plodnosti (R. Böckh), tabulky sňatečnosti (G. von Mayr), tabulky rozvodovosti a podobně. Tabulky se mohou konstruovat z transversálního (průřezového napříč generacemi) nebo longitudinálního (generačního) pohledu. Mohou být úplné (podle jednotek věku) nebo zkrácené (podle věkových skupin). Pro země, kde nejsou k dispozici podrobná data, se využívá tzv. modelových úmrtnostních tabulek, kde se za pomoci jednodušších i složitějších matematických postupů tyto tabulky počítají.
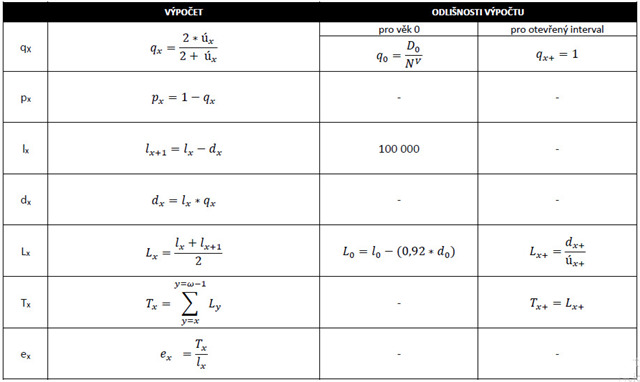
U této keše si zkusíte vypočítat úplnou úmrtnostní tabulku, zvlášť podle pohlaví. Na obrázku výše máte k dispozici tabulku se vzorci jednotlivých tabulkových funkcí, velmi doporučuji si ji vytisknout a dělat si poznámky. Nebojte se, výpočty spolu projdeme krok po kroku. Jednotlivé tabulkové funkce jsou následující:
qx = kvocient úmrtnosti (odhad pravděpodobnosti úmrtí mezi přesnými věky x a x+1)
px = pravděpodobnost dožití
lx = tabulkový počet dožívajících se přesného věku x
dx = tabulkový počet zemřelých mezi přesnými věky x a x+1
Lx = tabulkový počet žijících v dokončeném věku x (tzv. tabulková populace)
Tx = tabulkový počet let zbývající k dožití tabulkovou populací ve věku x (tzv. počet člověkolet)
ex = naděje dožití (střední délka života) ve věku x (podíl počtu let života připadajících v průměru na každého jedince ve věku x z dané generace)
Jako vstupní data budete pro výpočty potřebovat:
Px = střední stav obyvatel podle věku a pohlaví
Dx = počet zemřelých podle věku a pohlaví
NV = počet živě narozených dětí podle pohlaví
A konečně, pro výpočet kvocientů úmrtnosti bude třeba nejprve spočítat míry úmrtnosti podle věku a pohlaví (úx), které již umíte z předchozích keší, ale pro jistotu:
úx = Dx / Px
Postup pro tvorbu úmrtnostní tabulky
A) Stáhněte si příslušný soubor na odkazu níže, kde máte předpřipravený mustr pro vytvoření úmrtnostní tabulky. Zkopírujte data do Excelu. Máte k dispozici střední stav obyvatel podle věku (Px), počty zemřelých podle věku (Dx) a živě narozené děti (NV). Tabulky jsou připravené dvě, nejprve za muže a poté za ženy. Doporučujeme spočítat tabulku za muže a vzorce poté zkopírovat do tabulky pro ženy, usnadníte si tak práci.
B) Vytiskněte si tabulku se vzorci. Povšimněte si, že některé ukazatele mají odlišný způsob výpočtu u věku 0 a pro poslední otevřený interval (věk 100+). Velmi doporučujeme si příslušné „výjimky“ v Excelu podbarvit. Kořen tabulky a kvocient úmrtnosti pro otevřený interval už v mustru máte předvyplněný, viz dále.
C) Nejprve spočítejte míry úmrtnosti podle věku (úx), vzorec máte v listingu (nikoliv v tabulce, protože není defacto tabulkovou funkcí). Nyní již máte vše připraveno, jde se na tabulku!
D) Spočtěte kvocienty úmrtnosti podle věku (qx) za pomoci nepřímé lineární metody výpočtu. Pozor, pro věk 0 je potřeba kvocient spočítat jako podíl zemřelých ve věku 0 a živě narozených. Dále, poslední otevřený interval musí být roven jedné, jelikož, logicky, všichni v posledním otevřeném věkovém intervalu zemřou (pravděpodobnost úmrtí je 100%).
E) Následuje výpočet pravděpodobnosti dožití (px), který je pouze prostým doplněním kvocientu úmrtnosti do jedné.
F) Přichází první náročnější část. Tabulkový počet dožívajících se přesného věku x (lx) a tabulkový počet zemřelých mezi přesnými věky x a x+1 (dx) je třeba počítat současně, protože jsou jejich vzorce vzájemně provázané. V souboru již máte předvyplněný tzv. kořen tabulky, který dosahuje hodnoty 100 tisíc (l0), ten ponechte a počítejte až od počtu dožívajících se přesného věku 1. Vzorec je v podstatě velmi jednoduchý, odečítáte od sebe vždy „l“ a „d“ v předchozím roce, tedy u věku 1 to bude 100 000 (l0) a tabulkový počet zemřelých mezi přesnými věky 0 a 1 (d0). Vzorec překopírujte až dolů, i když ještě (dx) nemáte vypočítané. Teď spočítejte tedy (dx), které získáte jednoduchým násobením (lx) a (qx) ve stejném roce. Opět vzorec „stáhněte“ až dolů a máte (lx) a (dx) spočítané.
G) Nyní spočítejte tabulkovou populaci (Lx). Pozor, pro věk 0 je potřeba použít jiný vzorec, protože v tomto případě nelze vycházet z počtu zemřelých v dokončeném věku 0. Proto se od kořene tabulky odečítá tabulkový počet zemřelých, násobený korekčním koeficientem, který je roven 0,92. Jedná se o podíl zemřelých v prvním půlroce života. Od věku 1 již počítejte podle standardního vzorce, kdy je (Lx) rovno prostému průměru mezi „l“ v tomto a následujícím roce; pro věk 1 počítáte tedy (L1) jako průměr (l1) a (l2). Pozor, pro poslední otevřený věkový interval (100+) je vzorec opět jiný, tentokrát počítáte podíl tabulkového počtu zemřelých v poslední věkové skupině (d100+) a míry úmrtnosti ve věku 100+ (ú100+).
H) Máte před sebou zřejmě nejobtížnější část tabulky, a to počítání počtu člověkolet (Tx). Tady je postup jiný, začněte od poslední věkové skupiny (T100+), která se rovná tabulkové populaci v poslední otevřené věkové skupině (L100+). Nyní uděláte postup, kterému se říká kumulace zdola. (T99), tedy počet člověkolet ve věku 99 let bude rovný součtu (T100+), tedy počtu člověkolet v otevřeném intervalu a tabulkové populaci ve stejném roce, ve kterém je počítaný příslušný počet člověkolet, tedy (L99). Vzorec pak překopírujte směrem nahoru až k (T0) a máte hotovou kumulaci zdola.
I) Poslední výpočet, který je nejdůležitější z celé úmrtností tabulky, tedy ukazatel naděje dožití (ex), už vypočítáte snadno. Jedná se o podíl (Tx) a (lx).
Jak na keš
Luštění bude, podobně jako u dvojky a pětky, ryze praktické. Zkusíte si vypočítat úmrtnostní tabulky za muže a ženy v Česku v roce 2018. Berte to jako završení cesty k základním demografickým vědomostem, další počítání už nebude ;-). Data ve formátu .txt získáte na odkazu níže, společném pro všechny keše série. Text je oddělený tabulátory, takže pro zkopírování do Excelu stačí označit vše (ctrl+a), zkopírovat (ctrl+c) a následně vložit do prázdné buňky (ctrl+v), do buněk se automaticky rozdělí. Pozor! Chystáte se stáhnout soubor, který obsahuje více podrobností, které potřebujete k nalezení této geocache. Já, jakožto vlastník této cache, prohlašuji, že stažení tohoto souboru je bezpečné, ačkoliv soubor nebyl Groudspeakem ani reviewerem kontrolován na možný škodlivý obsah. Stažení tohoto souboru je na Vaše vlastní riziko.
[https://drive.google.com/drive/folders/1ibGve9oakKTSyG-NKdzQ4rytxz1DXfzq?usp=sharing]
1) Za A dosaďte naději dožití při narození za muže (e0M), kterou zaokrouhlete na 2 desetinná místa a ciferujte.
2) Za B dosaďte naději dožití při narození za ženy (e0Ž), kterou zaokrouhlete na 2 desetinná místa a ciferujte.
3) Za C dosaďte naději dožití ve věku 70 let za muže (e70M), kterou zaokrouhlete na 2 desetinná místa a ciferujte.
4) Za D dosaďte naději dožití ve věku 70 let za ženy (e70Ž), kterou zaokrouhlete na 2 desetinná místa a ciferujte.
5) Za E dosaďte pravděpodobnost dožití mezi přesnými věky 80 a 95 let (tedy s jakou pravděpodobností se osoba v přesném věku 80 let dožije přesného věku 95 let) za muže. Výsledek získáte tak, že vydělíte tabulkový počet mužů dožívajících se přesného věku 95 let (l95M) a tabulkový počet mužů dožívajících se přesného věku 80 let (l80M). Výsledek uvádějte v procentech (vynásobte jej stem), zaokrouhlete na 2 desetinná místa a ciferujte.
6) Za F dosaďte pravděpodobnost dožití mezi přesnými věky 80 a 95 let (tedy s jakou pravděpodobností se osoba v přesném věku 80 let dožije přesného věku 95 let) za ženy. Výsledek získáte tak, že vydělíte tabulkový počet žen dožívajících se přesného věku 95 let (l95Ž) a tabulkový počet žen dožívajících se přesného věku 80 let (l80Ž). Výsledek uvádějte v procentech (vynásobte jej stem), zaokrouhlete na 2 desetinná místa a ciferujte.
Výsledné souřadnice jsou:
N 50° 0(F-E).CAE E 014° 4(F-C).(B-D-E)(F-2*D)(B-A)
Zdroje: KALIBOVÁ, K. (2001): Úvod do demografie. Karolinum, Praha, 52 s.; Český statistický úřad; Sociologická encyklopedie